in den letzten Tagen war ja offenbar mal wieder kurz das Thema „Datenschutz“ in den Medien; vor allem im Zusammenhang mit facebook. Es soll dort einen Datenklau der Firma Cambridge Analytics gegeben haben. Mal ganz abgesehen vom komplett falschen Begriff hat es überhaupt keinen Diebstahl gegeben. Soweit das bisher bekannt ist, wurden alle Daten im Sinne der facebook-AGBs verwendet. Ein interessantes Interview dazu kann man hier lesen.
Im Kinofilm-Kontext spricht man hierbei von Piraterie, auch wenn für Piraterie der Begriff Diebstahl (oder besser Raub) auch ganz gut passt. Für solche recht neuen Vorfälle im Digitalen haben wir in unserer Sprache einfach noch keine perfekten Beschreibungen, wobei „Missbrauch“ wohl schon in die richtige Richtung geht.
Und wenn man sich nun im Internet so ein bisschen umschaut, sieht man überwiegend Kommentare in der Art „selber schuld, man muss sich bei facebook ja nicht anmelden!“. Das ist leider grottenfalsch! Es stimmt zwar, dass man sich bei facebook (oder jedem anderen Dienst) nicht anmelden muss, aber zu glauben, dass dadurch keine Daten über die eigene Person gesammelt werden, ist nicht nur äußerst naiv sondern eben auch falsch. Das liegt vermutlich einfach an der ziemlich schlechten (Aus-) Bildung der „normalen Bevölkerung“, was Internet- und Computer-Themen angeht oder einer Wunschvorstellung.
Zum aktuellen Stand sammelt so quasi jede Internet-Seite jede Menge Informationen über die Besucher. Ich habe darüber schon mal kurz letztes Jahr geschrieben, als (mir) bekannt wurde, dass selbst auf so einer angeblich „seriösen Seite“ wie der der Süddeutschen Zeitung mehr als 40 der sogenannten „Tracker“ aufgerufen werden. Jeder einzelne dieser Aufrufe ist dazu da, Daten zu sammeln. Es gibt verschiedene Seiten im Internet, die zeigen, welche Infos so alle selbst ohne irgendwelche IT-Tricks (oder gar Programmierungen) gesammelt werden können (z.B. dieser „Browser Mirror„). Neben der IP (mit der man übrigens schon ziemlich genau den Standort bestimmen kann, auch ganz ohne GPS-Ortung!) noch so andere Infos wie den verwendeten Browser, dessen Version, das Betriebssystem, dessen Version, wie groß der Bildschirm ist (zumindest die aktuelle Auflösung), die Größe des Browser-Fensters, die aktuelle Zeitzone und „woher“ ich gerade gebrowsed bin. All diese Infos sind frei verfügbar und wenn diese nun auf allen (oder zumindest vielen) Seiten gesammelt werden, die ich so besuche, werde ich auf einmal ganz schön gläsern.
Wenn jetzt nun noch diese „Social Media Like Buttons“ (oder Share/Teilen-Knöpfe) dazu kommen, gehen diese Daten auch noch an diese Social Media Firmen.
Dann gibt es noch jede Menge andere Dienste, die „frei“ im Internet zur Verfügung gestellt werden, ein Beispiel davon sind diese google-Schriftarten. Feiner Zug von google, einfach ein paar tolle Schriftarten „kostenlos“ zur Verfügung zu stellen. Im Gegenzug wissen sie aber natürlich auch, wo und wie diese verwendet werden. Zusätzlich bieten sie noch tolle Statistik-Tools an, die für manche Webseiten-Betreiber interessant sind, aber an google natürlich noch sehr viel mehr wertvolle Daten liefern.
Und mit all diesen Methoden (dabei sind das nur die offensichtlichen) werden Daten über jede/n einzelne/n Internet-NutzerIn gesammelt, noch bevor man sich einmal irgendwo eingeloggt hat oder etwas in eine Suchmaschine getippt hat. Mit den Nutzen des Internets geht es dann weiter. Ihr kennt bestimmt diese Captchas, diese Bilderrätsel im Stile von „Auf welchen Kacheln sind Verkehrsschilder zu sehen?“. Das ist – vermutlich – auch ein google-Dienst und wie jeder Umsonst-Dienst, oder besser gesagt: Kosten-freie Dienst, muss das natürlich anders bezahlt werden: mit unseren Daten. Neben den üblichen Daten, die dabei gesammelt werden, trainieren wir damit ganz nebenbei auch die Maschinen/Algorithmen von google beim Thema Bilderkennung.
Falls ich jetzt nur einen einzigen Browser nutze, können z.B. die angesprochenen Social Media-Elemente auf jeglicher Webseite sehr genau mit meinem zugehörigen Social Media Profil in Zusammenhang gebracht werden.
Ich probiere aus, diverse Browser für diverse Zwecke zu nutzen. Dadurch sind die grundlegenden Daten wie Betriebssystem oder Bildschirm immer noch gleich, aber es kommt zumindest eine gewisse Unschärfe dazu und die Wahrscheinlichkeit ist eben keine 100% mehr, sondern deutlich geringer.
Sobald ich wieder aus dem Urlaub zurück bin, werde ich jedoch mit entsprechenden Plugins solche Tracker noch rigoroser blocken lassen, als ich es jetzt schon mache (z.B. durch Adblocker).
Außerdem leere ich regelmäßig meine Cookies und den Browser-Verlauf. Dadurch geht zwar etwas Komfort verloren, aber ich finde, für etwas mehr Datenschutz, bzw. niedrigere Wahrscheinlichkeitswerte für die Berechnungen von google, facebook, twitter, etc. ist es mir das wert.
Dazu kommen noch alle weiteren Daten, die ich irgendwann mal preisgebe, z.B. dadurch, dass ich mich irgendwo angemeldet habe, bei einem Gewinnspiel mitgemacht habe, mal eine Internet-Suche durchgeführt habe, etc. Alleine google weiß anhand der eingegebenen Daten ziemlich genau, wo eine Grippewelle anrollt (Beispiel) und einiges mehr. Wer jetzt sagt: „Na und – mir doch egal!“ den will ich sehen, wenn die Apotheken anhand solcher gekauften Informationen passend die Preise von Grippemitteln „anpassen“ (i.e. drastisch erhöhen). Dass diverse Internet-Händler verschiedene Preise für das gleiche Produkt anbieten, je nachdem mit welchem Gerät man die Seite aufruft (kleine Daumenregel: bei Apple wirds teurer, weil die Leute Geld haben) ist ja schon länger bekannt.
Und dieses „Feature“ bei google hat mich letztens auch etwas überrascht: google weiß ziemlich genau, wie viele Leute an welchen Tagen zu welchen Zeiten in Geschäften sind.
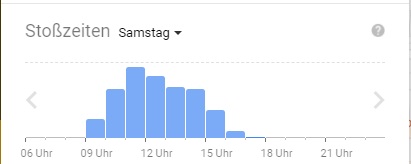
Es ist natürlich technisch eine Kleinigkeit, denn das eigene Smartphone weiß immer, wo es sich gerade befindet (ich wiederhole mich: auch ohne aktiviertem GPS!) und mit android als quasi-Standard bei Smartphone-Betriebssystemen können sie recht gut solche Voraussagen treffen. Wenn ich einen google-Account habe und mich damit auf meinem Smartphone angemeldet habe, sind diese Daten auch nicht mehr anonym, sondern es gibt eine fast 100% Wahrscheinlichkeit, dass es sich dabei um „mich“ handelt.
Dabei sind die schlauen Leute bei den IT-Firmen natürlich immer einen Schritt voraus. Sie denken sich jede Menge Sachen aus, wie man die Benutzer durchleuchten kann und die somit gewonnenen Daten mit möglichst viel Gewinn verwerten kann. Ein Beispiel davon waren z.B. mal diese Flash-Cookies, die doch recht lange unbemerkt Daten sammeln konnten, bis es Gegenmittel dagegen gab (die jetzt vermutlich immer noch von den allermeisten Menschen nicht eingesetzt werden).
Und diese kurze Abhandlung an der Oberfläche behandelte jetzt hauptsächlich die Desktop-Welt. Und mir ist bewusst, dass ich damit bestimmt einige Leser abgehängt habe.
Im mobilen Bereich sieht das nochmal anders aus. So ein Smartphone ist nichts anderes als eine große Wanze, die ich freiwillig mit mir trage. Über 80% davon haben ein android-Betriebssystem, das auch wieder von google bereit gestellt wird. Was darin genau passiert, weiß vermutlich niemand so genau. Letztendlich sind es ca. 1,5 Milliarden (!) Geräte mit diversen Sensoren, Kameras und Mikrofonen (wer weiß schon, wann die etwas aufnehmen). Durch die aufgespielten Programme (Apps) kann vermutlich niemand mehr gewährleisten, was da wirklich passiert. Wem ist es nicht schon mal passiert, dass er/sie über ein Thema gesprochen hat und dann „zufällig“ eine Werbung zu just diesem Thema irgendwo aufgetaucht ist? Ja, das geht jetzt in Richtung Spekulation und könnte tatsächlich wirklich Zufall sein; wenn ich über ein Thema spreche, habe ich ja vermutlich schon ein gewisses Interesse daran und schon mal Daten in eine Suchmaschine dazu eingegeben.
Beim Thema „mobil“ wird es noch viel komplizierter. Mein Ansatz dabei ist: ein google-freies Betriebssystem nutzen (Alternative: ohne Apple/Microsoft/etc. falls es das gibt) und soweit wie möglich auf Open Source Apps setzen, dazu gibt es einen eigenen App-Store. Diese könnten von „mir“ überprüft werden, was sie tun (wenn ich es verstände und die Zeit dazu hätte) oder ich vertraue einfach darauf, dass „die Internet-Community“ hier als Korrektiv agiert. Dass (große) Firmen mit ihren geschlossenen, proprietären Produkten etwas gutes für mich wollen, ist nach all den bisherigen Erfahrungen doch ziemlich ausgeschlossen.
P.S. ja, das hat alles ziemlich wenig mit meinem aktuellen Urlaub zu tun, aber ich dachte mir, dass ich mich dazu einfach mal äußern muss. Mein Plan ist es auch, einen kleinen Workshop über das Thema „Internet-Sicherheit und Datenschutz“ in Stuttgart anzubieten, wenn ich wieder zuhause bin; ein großes Thema dabei werden auch „Passwörter“ sein.
P.P.S. wer noch tiefer in diese Materie einsteigen will und auch ein paar Links haben will, die zeigen, welche Daten facebook, Windows, google, etc über „mich“ gespeichert hat (inkl. der Unterfirmen, wie z.B. youtube), der sollte sich mal diesen Twitter-Thread anschauen.
Schreibe einen Kommentar